Nagios является программой мониторинга информационных систем на основе открытого кода. Продукт является практически стандартом для систем мониторинга. Он позволяет (в том числе):
- контролировать хосты (загрузка процессора, использование диска, журналы и т. д.) с разнообразными операционными системами - Windows, Linux, AIX, Solaris и т. д.;
- контролировать сетевые службы (SMTP, POP3, HTTP, SSH и т. д.);
- подключать дополнительные модули расширения (плагины) на любом языке программирования (Shell, C++, Perl, Python, PHP, C# и др. - архитектура модулей должна быть открыта), использовать собственные способы проверки служб;
- осуществлять параллельную проверку систем (для повышения производительности);
- отправлять оповещения в случае возникновения проблем с помощью электронной почты, сообщений SMS и т. п.;
- автоматически реагировать на события службы или хоста.
Установка Nagios
Nagios является OpenSource-проектом, который доступен для установки как в исходных кодах, так и в подготовленных пакетах для различных клонов Linux. Понятно, что установка из исходных кодов имеет более свежую версию, чем подготовленные пакеты.
Установка из подготовленных пакетов осуществляется по правилам соответствующей версии операционной системы. Например, для Ubuntu команда будет выглядеть примерно так:
apt-get install nagios2
Это гарантирует установку всех необходимых для его работы библиотек и является самым простым способом, рекомендуемым для обычных пользователей.
Процедура быстрой установки программы на Ubuntu описана на сайте в разделе документации (http://nagios.sourceforge.net/docs/3_0/quickstart-ubuntu.html). Обратите только внимание на то, что за установкой из исходных кодов должна последовать и установка необходимых плагинов и дополнений.
После завершения установки работу программы можно проверить, открыв страницу http://localhost/nagios/ (вместо localhost следует использовать имя сервера Nagios в случае открытия страницы с удаленного компьютера). На запрос параметров авторизации необходимо ввести имя nagiosadmin и тот пароль, который вы назначили для этой учетной записи на предыдущих шагах.
На рис. 7.14 показана одна из страниц программы - структура контролируемой Nagios небольшой системы (схема строится в Nagios автоматически).
Рис. 7.14.
Схема сети в Nagios
Немного о логике работы Nagios
Nagios можно представить условно в виде двух частей: сервера (собственно о его установке и велась речь в предыдущем подразделе) и клиента, т. е. системы, которая контролируется при помощи агента или без его установки.
Существуют различные версии агентов, устанавливаемых на операционные системы. Наиболее часто для систем на основе Linux используется программа NRPE (ссылка на этот плагин присутствует на официальном сайте Nagios - http://www.nagios.org/), а для Windows-компьютеров - NSClient++ (http://trac. nakednuns.org/nscp/).
- Примечание
Исторически первым клиентом для Windows был вариант программы NPRE. В целях совместимости в NSClient++ сохранен протокол, используемый в NPRE. Вы можете в настройках клиента указать использование как любого варианта работы, так и обоих (некоторые плагины, например, разработаны под конкретную версию клиента). Учтите, что в некоторых случаях NPRe предоставляет больше возможностей для контроля, например, с его помощью легко настроить выполнение сценариев на самой контролируемой системе.
Обратим внимание читателя на то, что для каждого клиента должна быть настроена конфигурация так, как описано в последующих разделах.
При помощи клиентов происходит активный мониторинг работы: сервер инициирует на клиенте заданную настройками команду и анализирует полученные данные. Кроме того, возможен пассивный режим работы в тех случаях, когда данные на сервер пересылаются по инициативе клиента. Например, так происходит обработка SNMP-трапов.
Как уже говорилось, для получения информации от клиента на сервере Nagios запускаются специальные команды (или программы). В терминах Nagios эти команды принято называть плагинами (plugin).
- Примечание
Плагины несложно найти в Сети: с сайта Nagios есть ссылка на проекты на SourceForge.net, можно использовать сайт обмена плагинами http://www. monitoringexchange.org/ и другие источники.
Для того чтобы система мониторинга могла их использовать, такие команды должны быть описаны в специальном конфигурационном файле - commands.cfg. Именно эти описания в терминах Nagios и называются командами контроля.
Кроме описания самой команды, системе мониторинга надо знать, какие системы проверять, как часто запускать команду проверки, надо ли делать перерывы в ее использовании (например, не выполнять в определенные дни недели или в заданные периоды суток и т. п.). Совокупность таких настроек в Nagios принято называть службой (service), а определяются они отдельным блоком в файле, описывающим параметры контролируемой системы. Поскольку параметров в службе много (около полутора десятков) и многие из них обычно повторяются, то принято описывать повторяющиеся части в шаблонах (template), а непосредственно в описании службы просто указывать на такой шаблон (описания шаблонов хранятся в файле templates.cfg). Обратите внимание, что в шаблонах допускаются вложения: какую-то часть параметров можно выделить в отдельный шаблон и использовать его в других описаниях.
Каждая контролируемая система должна быть описана в конфигурации Nagios. Для удобства делается это в отдельных файлах (по типам устройств), которые при старте сервера включаются в общую конфигурацию. Первоначально ссылки на эти файлы "по направлениям" закомментированы, поэтому при необходимости начала контроля какого-либо класса устройств прежде всего следует удалить символ "#" в соответствующей строке файла nagios.cfg, а потом добавить блок описания системы в надлежащий файл.
В результате Nagios периодически выполняет на контролируемых системах заданные команды, собирает результаты и в случае возникновения критического события оповещает операторов. Результаты контроля можно сохранять (по умолчанию данные о производительности не хранятся) и представлять в графическом виде для анализа (см. разд. "Построение графиков в Nagios”). Также Nagios позволяет назначить команды, которые будут выполнены при возникновении событий. Таким способом можно автоматически устранять возникающие неисправности.
Если в системе будет контролироваться много компьютеров и устройств, то их удобно сгруппировать. В Nagios можно создать группы из компьютеров (устройств) и служб. Например, если нужно наблюдать за состоянием всех служб на серверах, то следует создать группу, в которую включить названия этих систем. А если вы хотите контролировать состояние, например, службы разрешения имен DNS, которая работает на нескольких физических системах, то в этом случае удобно создать группу для службы: достаточно будет видеть состояние всей группы как нормальное, чтобы быть уверенным в работе служб DNS на всех компьютерах. Так можно упростить администрирование и настройки мониторинга.
Из общих конфигурационных настроек отметим еще и параметры операторов - тех людей, кому программа будет отправлять сообщения в случае возникновения тех или иных событий. В Nagios индивидуальных операторов также можно объединять в группы и настраивать отправку сообщений определенного типа в конкретной группе специалистов. Также можно настраивать периоды времени. Их можно использовать для применения, например, различных типов контроля в рабочие и выходные дни, для разных способов оповещения администраторов (например, днем по электронной почте, а ночью - на пейджер) и т. д.
Оповещения могут эскалироваться: в случае появления повторяющихся событий оповещение может быть послано по иерархии следующему специалисту.
Структура конфигурационных файлов Nagios
Список стандартных файлов конфигурации Nagios приведен в табл. 7.1.
Таблица 7.1.
Список конфигурационных файлов Nagios
|
Имя файла |
Назначение |
|
Файл основных настроек конфигурации. Содержит имя и адрес администратора Nagios, ссылки на файлы конфигурации, импортируемые при старте системы |
|
|
Файл описания ресурсов. Содержит синонимы для скрытия путей фактического расположения команд Nagios от конечного пользователя для повышения безопасности |
|
|
Параметры настроек Web-сервера. В этом файле описываются дополнительные пользователи Nagios и предоставленные им права доступа |
|
|
Папки objects и др. |
Папки с отдельными файлами, которые импортируются в конфигурацию при старте Nagios. Эти папки описаны в файле nagios.cfg |
Описание команд Nagios
Команды Nagios описываются в файле commands.cfg (путь по умолчанию /usr/local/nagios/etc/object/commands.cfg).
На практике в файле commands.cfg обычно необходимо указать расположение исполняемого файла, его название, которое будет использовано в Nagios, и параметры строки запуска. По умолчанию в файле конфигурации установленной системы уже содержатся некоторые описания типовых команд проверки (проверки пингом - check_ping, проверки http-сервера - check_http и многие другие). По этим образцам легко можно создать собственные команды проверки, хотя обычно используют готовые разработки, которые, практически для любого варианта контроля, можно легко найти в Сети. Далее приведен пример описания простейшей команды - проверки достижимости хоста при помощи команды ping:

Это описание создает команду с именем check-host-alive, в качестве исполняемого файла используется команда check_ping из установленных утилит Nagios. Символы, заключенные в знаки доллара, указывают используемые переменные. В терминах Nagios это макросы (macros), которые заменяются значениями в момент выполнения. Поскольку обычно мы привыкли к другому определению макросов, в этой книге будем называть эти названия переменными. $hostaddress$ традиционно заменяется при вызове на имя тестируемой системы, а $arg1$, $arg2$ и т. д. - последовательно на аргументы, указываемые в описании службы. Ключи w и c определяют значения, которые будут использованы для формирования статуса предупреждения (w) или ошибки (с). Как правило, можно указывать абсолютные или относительные значения (или все вместе: в типовой конфигурации, например, параметр w указывается как 3000.0,80%). Последний ключ (-р) указывает, что команда ping должна послать пять проверочных пакетов.
Службы Nagios
Службы обычно описываются в файлах конфигурации отдельно для каждого типа контролируемых систем (в общую конфигурацию Nagios такие файлы импортируются директивами cgf_file=... в файле nagios.cfg). Построение файлов конфигураций начинается с описания шаблонов, за которыми следуют описания хостов и потом описания служб.
В описании службы уже можно не повторять общие значения из шаблонов, поэтому типовое определение службы может выглядеть примерно так:

В этом примере служба с названием Memory Usage использует для работы настройки из шаблона generic-service для хоста, описанного под именем winserver. В качестве команды служба запускает check_nt с параметрами командной строки memuse и -w 80 -c 90 (вторые параметры указывают, какое возвращаемое значение используемой памяти нужно считать критическим - 90%, а для какого установить состояние в предупреждение - от 80 до 90%; сами параметры перечисляются через символ "!").
Обычно для контроля однотипных устройств можно использовать одинаковую команду. В этом случае в описании службы достаточно перечислить все такие устройства через запятую:

Для служб можно определять зависимости (dependencies). Делается это для того, чтобы скрыть "лишние" предупреждения. Например, если часть систем находится в локальной сети после маршрутизатора, то можно определить зависимость их от этого устройства. Понятно, что если этот маршрутизатор выйдет из строя, то и все устройства, находящиеся за ним, окажутся недоступными. Настройка зависимости позволит в случае его аварии скрыть предупреждения о недоступности зависимых устройств пока не восстановится работа коммутатора и не выполнять на них проверку состояния соответствующих служб.
Описание контролируемых систем в Nagios
Для удобства различные типы контролируемых систем принято описывать в различных конфигурационных файлах. Перечень типовых используемых файлов конфигураций приведен в usr/local/nagios/etc/nagios.cfg, причем часть файлов закомментирована. Так, если потребуется контролировать коммутаторы в сети, то раскомментируйте строку #cfg_file=/usr/local/nagios/etc/objects/switch.cfg и т. д.
Само описание хоста (оно будет содержаться в файле windows.cfg, или switch.cfg, или printer.cfg и т. д.) минимально может выглядеть в этом случае следующим образом:

В описании хоста можно включать два параметра, которые будут определять действия, выполняемые в случае возникновения сбоев в работе системы:
Nagios будет выполнять команду проверки check-host-alive и, как только будет обнаружена смена состояния хоста, начнется выполнение программы server-reboot. Таким способом можно, например, запускать остановившиеся службы на контролируемых серверах, перезагружать системы и т. п.
Для удобства анализа хосты можно объединять в группы. Для этого необходимо описать группу в файле конфигурации следующим образом:
Так же, как и для служб, для хостов можно описывать зависимости одних систем от других.
Описание временных параметров
Временные параметры используются в различных конфигурациях: в описаниях хостов (период, когда нужно осуществлять мониторинг, и период, когда нужно отправлять сообщения), служб и контактов (периоды, когда можно отправлять сообщения по хостам и по службам). Синтаксис определения нового периода легко понятен по примерам, включенным в файл /usr/local/nagios/etc/objects/timeperiods.cfg.
Необходимо в описании дать название шаблону и перечислить построчно диапазоны времени, которые в него включаются. Причем можно использовать названия дней недели, месяцев и порядковые номера (последний/первый понедельник месяца). Периоды времени можно перечислять через запятую. При необходимости из одного шаблона можно исключать периоды, описанные в другом шаблоне, если использовать директиву exclude с последующим перечислением периодов времени (через запятую).
Использование встроенных в Nagios команд контроля
При стандартной установке Nagios и плагинов в нем присутствует ряд команд (плагинов), которые можно использовать для контроля систем. Список их приведен в табл. 7.2.
Таблица 7.2.
Список плагинов Nagios
|
Утилита |
Назначение |
|
Контроль обновлений систем Linux, осуществляемых с помощью команд apt-get. Позволяет запустить процесс обновления при соответствующей настройке |
|
|
Контроль мощности сигнала Wi-Fi стандарта Breezecom |
|
|
Этот плагин позволяет запускать на удаленной системе команды, используя протокол SSH |
|
|
Проверка соединения CLAMD (антивирусная программа) с удаленным хостом |
|
|
Проверка состояния хостов в кластере Linux |
|
|
Проверка доступности DHCP-серверов в сети |
|
|
Проверка работы DNS-службы на хосте (используется команда dig) |
|
|
Проверка объемов использования дискового пространства (собственных и примонтированных дисков) |
|
|
Проверка объемов использования дисков, подключенных по протоколу SMB (обычно это диски от Windows-систем) |
|
|
Проверка работы сервера DNS с использованием программы nslookup |
|
|
Плагин для настройки: просто возвращает численный параметр и строку, описанные при его запуске |
|
|
Проверка времени создания файлов |
|
|
Проверка службы Flexlm license manager |
|
|
Проверка ftp-соединения с удаленным хостом |
|
|
Проверка состояния принтеров Hewlett Packard c установленной картой JetDirect (проверка осуществляется с использованием протокола SNMP) |
|
|
Проверка http-соединений с удаленной системой. Проверка может осуществляться как по протоколу HTTP, так и по протоколу HTTPS. Можно контролировать время установки соединения, срок действия сертификатов сервера, а также ответ сервера (по поиску в ответе некоторой заданной строки, в том числе, допускается использование регулярных выражений) |
|
|
Проверка удаленных хостов по протоколу ICMP |
|
|
Проверка состояния локального диска (в Linux-системе) по S.M.A.R.T.-технологии |
|
|
check_ifoperstatus |
Проверка состояния работы сетевого интерфейса на заданной Linux-системе |
|
Проверка состояния сетевого интерфейса на заданной Linux-системе |
|
|
Проверка работы удаленного хоста по протоколу IMAP. Можно анализировать ответ сервера на посылаемую на него строку imap-запроса |
|
|
Проверка IRCD-плагина Nagios |
|
|
Проверка JABBER-подключения к удаленному хосту |
|
|
Проверка LDAP-сервера (можно отправить запрос на поиск соответствующего атрибута) |
|
|
То же проверка LDAP-сервера, только с использованием защищенных соединений (по протоколу SSL) |
|
|
Проверка загрузки Linux-системы |
|
|
Проверка журналов Linux-системы на наличие некоторой последовательности символов |
|
|
Проверка числа сообщений в очереди почтового сервера (работает с различными версиями sendmail, qmail) |
|
|
Проверяет заданную переменную в логе MRTG (Multi Router Traffic Grapher) на минимальное/максимальное значения (для контроля параметров производительности необходимо использовать check_mrtgtraf) |
|
|
Проверяет значения исходящего и входящего трафика коммутаторов, записанные в журнал MRTG. Требуется первоначальная установка пакета MRTG (http://ee-staff.ethz.ch/~oetiker/webtools/mrtg/mrtg.html) |
|
|
Проверяет состояние процесса Nagios на локальной машине |
|
|
Проверка NNTP-соединения с указываемым хостом |
|
|
То же, но с использованием протокола NNTPS |
|
|
NRPE плагин Nagios |
|
|
Этот плагин осуществляет сбор данных со службы NSClient на Windows-системах |
|
|
Проверка NTP-сервера. Вместо этого плагина рекомендуется использовать check_ntp_peer |
|
|
Проверка NTP-сервера. Позволяет оценивать, в том числе, дрожание (jitter) сигнала времени |
|
|
Этот плагин проверяет разницу времени между локальным сервером и указываемым удаленным серверов времени |
|
|
Используется для сбора данных с Novell-серверов. Требует установки дополнительных пакетов |
|
|
Проверяет подключение к серверу Oracle, позволяет оценить размеры баз данных и наличие свободного места, состояние буферов кэширования и т. д. |
|
|
Проверяет состояние Over-CR collector daemon на удаленной системе (http://www.molitor.org/overcr) |
|
|
Проверяет соединение с удаленной системой с использованием пакетов ping |
|
|
Проверка удаленных хостов по протоколу POP. Позволяет отправить на почтовый сервер строку запроса и проанализировать ответ сервера |
|
|
Проверяет состояние процессов Linux-системы |
|
|
Проверяет состояние службы REAL (RTCP-подключений) |
|
|
Проверяет состояние RPC-службы на указанном хосте |
|
|
Проверяет состояние аппаратных датчиков системы Linux. Информация с датчиков получается с помощью пакета lm_sensors |
|
|
Проверяет IMAP-подключение по безопасному каналу к серверу. Контролируется время ответа и содержание (по анализу ответа на заданный запрос), валидность сертификатов |
|
|
Проверяет SMTP-подключение к серверу. Ответ почтового сервера может анализироваться на наличие заданных строк. Также контролируется время отклика |
|
|
Проверка удаленных систем (и получение с них данных) по протоколу SNMP |
|
|
Проверяет POP-подключение по безопасному каналу к серверу. Контролируется время ответа и содержание (по анализу ответа на заданный запрос), валидность сертификатов |
|
|
Проверка подключения к SSH-серверу |
|
|
Проверяет SMTP-подключение по безопасному каналу к серверу. Ответ почтового сервера может анализироваться на наличие заданных строк. Также контролируется время отклика |
|
|
Проверяет свободное пространство в swap-файле локальной системы |
|
|
Проверка TCP-подключения к указанной системе. Проверяется наличие отклика, его время, наличие в отклике заданных строк и т. п. |
|
|
Проверка времени на указанном хосте |
|
|
Проверка UDP-подключения к указанной системе. Проверяется наличие отклика, его время, наличие в отклике заданных строк и т. п. |
|
|
Проверка состояния источников бесперебойного питания на локальной или удаленной Linux-системе. Для работы плагина требуется, чтобы в системе был установлен UPSD daemon (http://www.networkupstools.org) |
|
|
Проверка числа пользователей, вошедших в локальную систему |
|
|
Проверка уровня WI-FI-сигнала |
Каждый из этих плагинов содержит справочную информацию, описывающую особенности его применения (вывод справки по команде <плагин> -h).
Для того чтобы задействовать плагин для мониторинга систем, в Nagios должна быть описана использующая его команда. В файле commands.cfg приведено несколько наиболее часто употребляемых примеров контроля систем. При практическом использовании Nagios этот файл должен быть расширен за счет ваших собственных команд контроля.
Мониторинг серверов Windows в Nagios
Для мониторинга систем на основе Windows разработано несколько различных агентов. Наиболее часто используемыми из них являются NSClient++, NC_NET (http://sourceforge.net/projects/nc-net) и OpMonAgent (http://www.opmon.org/ project/opmonagent.zip). Функционал данных агентов практически идентичен, поэтому мы рассмотрим использование агента NSClient++, являющегося, на взгляд автора, наиболее популярным из упомянутого списка.
Агент NSClient++ доступен со страницы http://trac.nakednuns.org/nscp/. Эту программу можно загрузить как в виде архива (zip), так и установочным файлом (msi), причем для 32- и 64-битных платформ следует использовать различные версии агента. Если вы загрузили архив, то его необходимо распаковать в желаемую папку и установить службу Windows командой
NSClient++ -install
Удобнее воспользоваться msi-файлом, поскольку в этом случае мастер установка сразу внесет в конфигурацию агента часть настроек по результатам ваших ответов (рис. 7.15).

Рис. 7.15.
Настройка параметров программы NSClient++.
Настройки пользователя, введенные на этапе установки, будут сохранены программой в файле конфигурации
После установки необходимо разрешить взаимодействие службы с рабочим столом, для чего следует открыть свойства службы (Панель управления | Администрирование | Службы | найти службу NSClientpp... (полное название зависит от версии) и открыть ее свойства) и включить опцию Разрешить взаимодействие с рабочим столом .
Перед запуском службы следует обязательно проверить параметры ее работы. Для этого откройте файл nsc.ini (в папке установки агента) и снимите комментарий с тех строк, которые соответствуют модулям программы, предполагаемым к использованию для мониторинга системы. Достаточно подробные описания параметров конфигурации приведены в документации плагина на странице http://trac. nakednuns.org/nscp/wiki/doc/Configuration.
При настройке конфигурации следует исходить из принципа, что не следует включать больше опций, чем это необходимо в текущий момент. Например, если вы не планируете получать информацию посредством WMI-запросов, то и не стоит загружать модуль CheckWMI.dll.
Обратите внимание на возможность запуска агента в диагностическом режиме. При этом вы сможете как увидеть потенциальные ошибки в конфигурационном файле, так и отладить собственные запросы (рис. 7.16).

Рис. 7.16.
Окно программы NSClient++ в диагностическом режиме
Для запуска NSClient++ в диагностическом режиме достаточно в командной строке набрать
NSClient++ /test
В окне NSClient++ вы сможете, во-первых, увидеть результаты загрузки всех модулей, а во-вторых, вводить собственные команды и видеть результаты выполнения как запросов со стороны сервера Nagios, так и локальных команд. На рис. 7.16 показано окно отладки плагина, в котором введена команда CheckDriveSize ShowAll MinWarnFree=20% MinCritFree=10% Drive=D:\ и виден ответ системы.
Плагин NSClient++ позволяет контролировать параметры, приведенные в табл. 7.3. Подробности использования подробно описаны в технической документации (http://trac.nakednuns.org/nscp/wiki/CheckCommands) и по имеющимся примерам легко составить собственные команды контроля состояния Windows.
Таблица 7.3.
Параметры Windows, контролируемые NSClient++
|
Параметр |
Описание |
|
Контролирует размер файла или папки |
|
|
Контролирует размер свободного или использованного пространства жестких или сменных дисков (тип диска можно выбирать в команде) |
|
|
Контролирует файлы по критериям даты их создания, времени последнего доступа, записи в файл или по размеру файла |
|
|
Ищет сообщения об ошибках в файле журнала. Поскольку таких сообщения обычно много, использование данного контроля сильно загружает систему |
|
|
Контролирует загрузку процессора в течение задаваемого периода времени |
|
|
Контролирует время работы системы |
|
|
CheckServiceState |
Контролирует состояние службы Windows (критическое сообщение формируется в случае несоответствия фактического состояния службы заданному в качестве параметра в команде). Можно контролировать все службы одновременно с заданием исключения. В качестве названия службы надо указывать то, которое отображается в свойствах службы |
|
Контролирует состояние процессов Windows. Фактически позволяет наблюдать за состоянием процесса, найденного по имени исполняемого файла. Можно контролировать также по числу одновременно запущенных процессов |
|
|
Контролирует состояние виртуальной и физической памяти; доступен параметр количества записанных страниц памяти (commited pages) |
|
|
Контролирует значения счетчиков производительности. Объекты счетчиков желательно - в целях удобства использования - задавать в описаниях команд (служб) |
|
|
CheckAlwaysOK
|
Так называемые хэлперы. Возвращают заранее определенное значение (какое - можно судить по названию команды). Используются в процессах настройки и отладки системы |
Перечисленным списком не ограничиваются возможности контроля Windows-систем. Вы можете добавить контролируемые параметры, например, за счет использования внешних сценариев.
Мониторинг систем Windows может осуществляться на основе различных протоколов. Наиболее часто используемыми являются протоколы NSClient и NRPE (для "пассивного" мониторинга можно использовать также протокол NSCA, о котором более подробно можно прочесть в онлайновой документации). На практике можно использовать любой из них, необходимо только включить/выключить соответствующие модули в файле настроек клиента (nsc.ini). В то же время, на взгляд автора, протокол NRPE несколько более гибок в использовании и обеспечивает шифрование данных обмена. При использовании протокола NRPE синтаксис команд строится следующим образом:
check_nrpe ... -c <команда> -a <аргументы>
Например, проверка доступной физической памяти может быть осуществлена так:
check_nrpe -H 192.168.0.9 -c CheckMem -a MaxWarn=70% MaxCrit=>80% type=physical
Мониторинг Windows-систем на основе WMI
В состав NSClient++ входит модуль CheckWMI.dll, позволяющий контролировать Windows-систему с использованием инструментария WMI.
Модуль CheckWMI фактически состоит из двух подмодулей: CheckWMIValue и CheckWMI. Модуль CheckWMIValue оптимизирован для контроля численных значений. Например, текущей загруженности процессора (это число процентов загрузки) или разрешения монитора (число пикселов) и т. п. В этой команде вы можете просто указать контролируемые параметры и минимальные/максимальные допустимые для них значения, например, так:
CheckWMIValue "Query=Select PelsWidth from win32_DisplayConfiguration"
MinCrit=640 MinWarn=800 Check:Width=PelsWidth
Приведенная здесь команда составлена для использования в режиме отладки (nsclient++ /test). Она запрашивает разрешение дисплея по горизонтали и сообщает о критическом состоянии в случае, если оно равно или менее 640, и выдает предупреждение, если значение не превосходит 800. Из особенностей использования этой команды отметим, что после строки запроса (которая заключена в кавычки) нужно писать параметры минимальных/максимальных значений и только потом указывать название параметра, который контролируется командой (PelsWidth). Поясним также опцию Check, используемую в командной строке. После Check необходимо вписать название параметра, которое будет применяться в системе контроля (можно сохранить и название из описания в WMI, но часто более удобно ввести собственное название), и название, соответствующее объекту класса (то, которое отображается, например, в утилите просмотра WMI Object Browser).
Другие примеры (в том числе в вариантах для конфигурации Nagios) приведены на странице http://trac.nakednuns.org/nscp/wiki/CheckWMIValue.
Модуль CheckWMI нужно использовать в тех случаях, когда предполагается либо анализ строкового параметра, возвращаемого в результате WMI-запроса, либо запрос нескольких значений. При использовании CheckWMI строки запроса несколько усложняются из-за необходимости использования фильтров. Синтаксис CheckWMI описан на странице http://nsclient.org/nscp/wiki/CheckWMI/ CheckWMI. По своему построению запросы CheckWMI сходны с фильтрами, используемыми для анализа журналов работы системы.
Мониторинг серверов Linux в Nagios
Контроль работы серверов Linux осуществляется с использованием плагина NRPE, причем на сервере Nagios он должен быть установлен как плагин, а на контролируемой системе Linux - в качестве демона. Для установки может быть использована как подготовленная версия, так и исходные коды плагина.
Кроме стандартного комплекта администратор может использовать при мониторинге любой из доступных плагинов, которые широко представлены в Интернете.
Используя протокол NRPE, можно на контролируемом хосте вызвать команду check_nrpe для проверки другого хоста. Таким способом можно контролировать некоторую подсеть через один компьютер. При такой организации контроля на хосте, используемом в качестве прокси, обязательно должны быть установлены как демон протокола NRPE, так и плагин.
Мониторинг систем с использованием протокола SNMP
Для работы по протоколу SNMP в Nagios должен быть установлен соответствующий плагин. Он включен в состав плагинов Nagios, но воспользоваться им можно только в том случае, если предварительно был установлен пакет net-snmp. Поэтому, если предполагается использование SNMP-модуля, данный пакет необходимо загрузить с сервера http://net-snmp.sourceforge.net/, после чего заново перекомпилировать плагины и повторно установить их. Автор рекомендовал бы при новой установке сначала выполнить команду make clean, которая очистила бы настройки предыдущей инсталляции.
- Примечание
На сайте http://net-snmp.sourceforge.net/ необходимый пакет представлен только в исходных кодах или в RPM-формате.
После настройки возможности контроля по протоколу SNMP необходимо протестировать 1 работоспособность на простейших запросах. Например, проверить длительность работы устройства:
/usr/local/nagios/libexec/check_snmp -H <адрес_устройства> -C
sysUpTime. 0
В ответ вы должны получить примерно такое сообщение:
SNMP OK - Timeticks: (622339555) 72 days, 0:43:15.55 |
Команда check_snmp может запрашивать параметр, принимающий численное значение, и проверять соответствие его значения некоторому диапазону. Так, можно указать значения для состояния предупреждения и критического состояния (ключи -w и -с) или диапазон значений (через двоеточие). Обратите внимание, что если вы хотите, чтобы, например, критическим значением интерпретировалось бы возвращаемое число в диапазоне от а до b (b > a), то диапазон нужно указывать b:a. Если указать диапазон в "привычном" виде, как a:b, то если возвращаемое значение попадает в этот диапазон, то результат будет считаться нормальным состоянием, а если не попадает - то как предупреждение или критическое (в зависимости от использованного ключа). Кроме того, команда может проверять возвращаемое строковое значение (значение, с которым проверяется ответ, следует указать в ключе -s) или даже выполнять проверку с использованием регулярных выражений (ключи -r, -R). Также в запросе можно проверять сразу несколько параметров, перечисляя их OID через запятую, например так:
После того как запрос будет составлен и отлажен, достаточно описать новую команду в файле commands.cfg и добавить нужные службы в файлы описания контролируемых устройств.
В Сети можно найти достаточное число примеров настройки Nagios для контроля устройств с использованием протокола SNMP, которые можно применить на практике. Так, по адресу http://wiki.nagios.org/index.php/Howtos:snmp-apc-smart-ups содержится описание настроек, с помощью которых можно контролировать состояние источников бесперебойного питания от APC (состояние батареи, параметры напряжения, температуру и т. д.).
Мониторинг коммутационного оборудования
Активное оборудование сети - коммутаторы, концентраторы, модемы и т. п. контролируются по протоколу SNMP (управляемые модели). Можно получать состояния портов оборудования, выдавать предупреждения в случае возникновения на портах некоторого числа ошибок передачи пакетов, наблюдать за температурой устройства и количеством VPN-сессий. Достаточно только выбрать соответствующие идентификаторы по описанию для мониторинга по протоколу SNMP. В большинстве случаев этого достаточно для контроля.
Однако, кроме указанных параметров, администраторы часто хотят знать реальную загрузку оборудования, процент использования пропускной способности. Эти значения нельзя получить, запрашивая тот или иной параметр состояния оборудования. Они вычисляются на основе анализа периодически получаемых данных. Специально для такого мониторинга создана одна из самых популярных программ - MRTG. Ее возможности обработки параметров коммутаторов используются в Nagios.
Программа MRTG по протоколу SNMP с активного оборудования собирает статистику, которая при помощи плагина check_mrtgtraf впоследствии передается в Nagios для отображения.
После установки программы MRTG необходимо создать файлы настроек, в которых указать устройства и значения параметров, которые программа будет собирать. Эти настройки должны быть приведены в файле /etc/mrtg.conf. Формирование конфигурации MRTG достаточно сложная задача, поэтому в пакете предусмотрена специальная программа, которая автоматически опросит устройство и сформирует файл конфигурации - cfgmaker. При ее запуске в качестве параметров нужно указать строку community и адрес устройства. Вывод программы следует перенаправить в файл, значения из которого мы потом просто импортируем в файл настроек. В качестве имени такого файла удобно использовать имя (или адрес) опрашиваемого устройства:
cfgmaker community@адрес > /etc/mrtg/адрес.cfg
По итогам работы команды cfgmaker достаточно только оставить в файле конфигурации те блоки данных, которые предполагается анализировать для данного устройства. Учитывая, что по информации файла, программа создает заголовки и служебные описания на страницах графика, имеет смысл откорректировать названия и описания тех позиций, которые предполагается отображать на графиках. Поскольку анализировать пропускную способность по портам, к которым подключены оконечные устройства (серверы, рабочие станции) не имеет смысла, то целесообразно сохранить мониторинг пропускной способности только для магистральных портов (портов, которые подключены к другим коммутаторам или концентраторам).
После редактирования файла настроек можно запустить программу mrtg, указав в качестве параметра конфигурацию устройства. Для систем с кодировкой UTF-8 команда запуска будет выглядеть так:
env LANG=C /usr/bin/mrtg /etc/mrtg.cfg
При установке пакета MRTG в системе настраивается автоматический сбор информации с коммутаторов один раз в течение пяти минут. При желании этот период можно увеличить, если соответствующим образом отредактировать файл /etc/cron.d/mrtg.
Графики производительности по отдельным портам устройств можно просмотреть, если открыть в обозревателе папку http://nagiosserver/mrtg/ и выбрать соответствующий файл. При желании можно сформировать общий индексный файл для упрощения отображения. Делается это с помощью команды indexmaker. Необходимые ключи для формирования файла легко уточнить по справочной информации после вызова indexmaker -h.
Всед за описанной настройкой можно использовать команды Nagios check_mrtg и check_mrtgtraf для сбора данных производительности. Команда check_mrtgtraf требует указания следующих параметров:
check_mrtgtraf -F -a -w входящий,исходящий-c входящий,исходящий -e период_устаревания
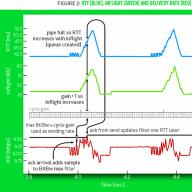
В этом примере параметр -a указывает, будет ли браться в учет максимальное значение (max) за период анализа или же программа оценит среднее значение (avg). После ключей w и c указываются пары лимитов для исходящего и входящего трафика по данному порту. По какому порту система будет контролировать данные, определяется выбранным файлом журнала. На рис. 7.17 приведен пример графика, формируемого пакетом mrtg.

Рис. 7.17.
График загрузки порта коммутатора
Использование собственных программ мониторинга
Nagios позволяет легко создать собственные плагины для мониторинга любой системы. В качестве таковых могут быть использованы любые исполняемые файлы. Необходимо только обеспечить, чтобы они сообщали код завершения работы в соответствии с табл. 7.4.
Таблица 7.4.
Коды возврата программ мониторинга системы для Nagios

При создании сценариев необходимо учитывать, что запускаться они будут от имени службы агента мониторинга. По умолчанию эта служба имеет максимальные права для локальной системы, но не может взаимодействовать с компьютерами сети. Если вы предполагаете использовать сценарии для сбора данных с других компьютеров, то необходимо либо предусматривать в сценариях операции подключения с указанием параметров соответствующей учетной записи, либо настроить агент для запуска от другого имени.
Построение графиков в Nagios
Команды Nagios, при помощи которых контролируются системы, возвращают не только состояние (хорошо или плохо), но и данные по конкретным параметрам (например, процент использования диска или число вошедших в систему пользователей). Эти данные по умолчанию не сохраняются, но могут быть использованы, например, для прорисовки графиков соответствующих служб.
Для реализации такой возможности необходимо установить дополнительный плагин. Одним из наиболее популярных плагинов для создания графиков в Nagios является пакет nagiosgraph, доступный к загрузке с сайта http://sourceforge.net/ projects/nagiosgraph/.
На рис. 7.18 представлен пример страницы контроля состояния служб, на которой при подведении курсора мыши к соответствующему параметру динамически отображается график его изменения. При желании администратор может перейти к выбору графика по любой службе и за заданный период времени.

Рис. 7.18.
Пример страницы с динамическим графиком
Настройка интерфейса Nagios
Для Nagios разработано много дополнений, которые позволяют настроить отображение данных мониторинга в соответствии с потребностями администратора. Так, вместо тактического обзора (рис. 7.19) можно использовать настраиваемые карты сети, на которых Nagios будет отображать состояние каждого устройства.

Рис. 7.19.
Стандартный вариант отображения суммарного состояния системы в Nagios
На рис. 7.20 (пример с сайта http://www.nagvis.org) приведен реальный вариант карты мониторинга, построенной при помощи пакета NagVis.

Рис. 7.20.
Отображение состояния сети при использовании пакета NagVis
В этом случае Nagios в реальном режиме времени будет отображать индикаторы по устройствам и линиям связи. При этом на карте возможно отображать суммарные состояния по группам (хостов и служб), значения фактического трафика по линиям связи и т. п. Понятно, что такие представления очень удобны при практическом использовании.
1 В примерах использован протокол SNMP версии 1. В реальных условиях обычно используется протокол версии 3, поэтому примеры необходимо дополнить параметрами аутентификации.
Nagios (Nagios Ain"t Gonna Insist On Sainthood) - программа с открытым кодом, предназначенная для мониторинга компьютерных систем и сетей. Она производит наблюдения, контроль состояния узлов и служб, оповещения администратора в том случае, если какие-то из служб прекращают (или возобновляют) свою работу.
В сегодняшней статье мы расскажем, как установить Nagios 4.1 на Ubuntu 15.04 .
Протестировать и посмотреть, что же из себя представляет Nagios и другие программы/сервисы/АТС вы можете перейдя в раздел .
Подготовка
Убедитесь, что на вашем сервере установлен полностью рабочий LAMP , если не установлен, то прежде чем продолжать, установите LAMP сервер. Установим следующие компоненты:
Sudo apt-get install build-essential libgd2-xpm-dev apache2-utils unzip
Создадим пользователя и группу Nagios
Создайте новую учетную запись пользователя nagios и группу nagcmd :
Sudo useradd -m nagios
sudo passwd nagios
sudo groupadd nagcmd
sudo usermod -a -G nagcmd nagios
sudo usermod -a -G nagcmd www-data
Скачиваем Nagios и плагины для него
На официальном сайте последняя версия значится как 4.1.0 release candidate 2 , ее и скачаем.
Cd /usr/src
sudo wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.1.0rc2.tar.gz
Скачиваем плагины
Sudo wget http://nagios-plugins.org/download/nagios-plugins-2.0.3.tar.gz
Установка Nagios
Переходим в папку, куда мы скачали Nagios и плагины и разархивируем с помощью команды:
Sudo tar xzf nagios-4.1.0rc2.tar.gz
Cd nagios-4.1.0rc2/
Выполняем следующие команды для компиляции и установки Nagios :
Sudo ./configure --with-command-group=nagcmd
sudo make all
sudo make install
sudo make install-init
sudo make install-config
sudo make install-commandmode
Устанавливаем Web-интерфейс Nagios :
Sudo make install-webconf
Если в процессе установки вы получили следующую ошибку:
/usr/bin/install -c -m 644 sample-config/httpd.conf /etc/httpd/conf.d/nagios.conf
/usr/bin/install: cannot create regular file ‘/etc/httpd/conf.d/nagios.conf’: No such file or directory
Makefile:296: recipe for target "install-webconf" failed
make: *** Error 1
Nagios пытается создать файл nagios.conf внутри /etc/httpd.conf/directory , но в системах Ubuntu файлы nagios.conf должны быть помещены в /etc/apache2/sites-enabled/directory . Используем тогда другую команду вместо sudo make install-webconf
Sudo /usr/bin/install -c -m 644 sample-config/httpd.conf /etc/apache2/sites-enabled/nagios.conf
Создадим учетную запись Nagiosadmin для входа в Web-интерфейс Nagios . Обязательно запомните задаваемый вами пароль, он вам понадобится при входе в Web-интерфейс.
Sudo htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
Перезапустим Apache, чтобы новые настройки вступили в силу:
Sudo systemctl restart apache2
Возвращаемся в папку, куда мы скачивали плагины и разархивируем плагины:
Cd /usr/src
tar xzf nagios-plugins-2.0.3.tar.gz
Переходим в разархивированный каталог:
Cd nagios-plugins-2.0.3/
Выполняем следующие команды для компиляции и установки плагинов:
Sudo ./configure --with-nagios-user=nagios --with-nagios-group=nagios
sudo make
sudo make install
Запускаем Nagios
Проверяем nagios.conf на наличие ошибок:
Sudo /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Если ошибок нет, запустим Nagios и добавим его в автозапуск:
Sudo service nagios start
sudo ln -s /etc/init.d/nagios /etc/rcS.d/S99nagios
Если при запуске Nagios вы увидели следующую ошибку:
Failed to start nagios.service: Unit nagios.service failed to load: No such file or directory.
[....] Starting nagios (via systemctl): nagios.serviceFailed to start nagios.service: Unit nagios.service failed to load: No such file or directory.failed!
Чтобы ее исправить нужно скопировать /etc/init.d/skeleton в /etc/init.d/nagios
Sudo cp /etc/init.d/skeleton /etc/init.d/nagios
Отредактируем /etc/init.d/nagios :
Sudo nano /etc/init.d/nagios
Добавив в самый конец следующее:
DESC="Nagios"
NAME=nagios
DAEMON=/usr/local/nagios/bin/$NAME
DAEMON_ARGS="-d /usr/local/nagios/etc/nagios.cfg"
PIDFILE=/usr/local/nagios/var/$NAME.lock
Сохраняем и выходим.
Финальный штрих - даем права на исполнение:
Sudo chmod +x /etc/init.d/nagios
и запускаем Nagios :
Sudo /etc/init.d/nagios start
Теперь в браузере вводим http://nagios-server-ip/nagios , в поле username вводим nagiosadmin и пароль, который мы задавали в процессе установки.


Нажмите на “Host” в левой панели консоли . Вы увидите, что на данный момент Nagios не мониторит ни одного хоста кроме самого себя.


На этом наша установка завершена. Пройдя по всей инструкции мы установили Nagios 4.1 на Ubuntu 15.04
Популярное решение для мониторинга — nagios позволяет реализовывать масштабируемые системы. Конфигурация для распределенных систем — длительный процесс, в рамках статьи реализуем мониторинг одного сервиса на удаленном хосте.
Работы по настройке будут выполняться на сервере с операционной системой CentOS 7 , для nrpe клиента также будет использоваться CentOS 7
На клиенте установим плагин nrpe и разрешим в его настройках подключение к серверу.
Nagios установка и настройка сервера мониторинга
Настройку начинаем на машине, которая будет выполнять роль nagios сервера. Установим необходимые пакеты:
yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzip
nagios работает через Apache , поэтому в списке устанавливаемых пакетов присутствует httpd
Переходим в корневой каталог с временными файлами и скачиваем в него при помощи wget последние релизы nagios и nagios-plugins
wget http://prdownloads.sourceforge.net/sourceforge/nagios/nagios-4.2.8.tar.gz
wget http://nagios-plugins.org/download/nagios-plugins-2.1.2.tar.gz
Создаем системных пользователя и группу
Добавляем пользователя nagios в группу nagcmd
usermod -a -G nagcmd nagios
usermod -a -G nagios,nagcmd apache
Поскольку используем CentOS httpd работает не от имени пользователя www-data, а от имени пользователя apache
Чтобы в дальнейшем не возникло конфликтов прав добавляем пользователя apache в группы nagios,nagcmd
Извлекаем содержимое скачанного архива
tar -zxvf nagios-4.2.0.tar.gz
Переходим в каталог с файлами nagios
Установку как nagios, так и nrpe в дальнейшем будем производить из исходников
./configure —with-command-group=nagcmd
В качестве опции при сборке указываем группу nagcmd
Компилируем
make install-commandmode
Рекурсивно копируем каталог с библиотеками в /usr/local на сервере
cp -R contrib/eventhandlers /usr/local/nagios/libexec
Также рекурсивно меняем владельца и группу владельца каталогов и файлов на nagios
chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
Пробуем запустить и посмотреть версию nagios указывая путь к основному конфигурационному файлу
Добавляем nagios в автозагрузку — система будет каждый раз запускать его при старте
systemctl enable nagios
Запускаем сервис
Аналогичные операции проделываем с веб-сервером
Задаем пароль пользователя nagios
При помощи htpasswd генерируем файл, который будет ограничивать доступ для пользователя nagiosadmin
htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
Установка основного пакета на этом завершена. Открываем интернет браузер и вводим в поисковую строку ip-адрес сервера, затем /nagios и попадаем в веб-интерфейс
Настройка мониторинга сервиса на удаленном хосте
Идем на другую серверную машину, которая будет выполнять роль nagios-клиента
Переходим в каталог /tmp/
Распаковываем nagios-plugins-2.1.2
tar -zxvf nagios-plugins-2.1.2
cd nagios-plugins-2.1.2
Компилируем указывая пользователя и группу nagios
./configure —with-command-user=nagios —with-nagios-group=nagios
Теперь устанавливаем nrpe plugin
Сначала дополнительно ставим из репозитория openssl-devel, если он уже установлен — шаг пропускаем (необходимо также присутствие пакета и на nagios сервере)
yum -y install openssl-devel
Можно установить и из репозитория
yum install nagios-plagins-all nagios-plagins-nrpe
Если нужна свежая версия, что так
Скачиваем пакет
wget http://sourceforge.net/projects/nagios/files/nrpe-2.x/nrpe-2.15/nrpe-2.15.tar.gz
Распаковываем tar.gz
tar -zxvf nrpe-2.15.tar.gz
Компилируем тем же способом, что и ранее
Идем на сервер nagios
Пробуем подключиться с сервера указывая после ключа -H IP адрес клиента
Получаем connection refused и отправляемся производить конфигурацию плагина
Стартуем nrpe на клиенте и добавляем сервис в автозагрузку
Открываем основной конфигурационный файл и в качестве значения в секции allowed_hosts указываем IP адрес сервера
mcedit /etc/nrpe/nrpe.cfg
allowed_hosts = 10.11.27.11
Возвращаемся на сервер
/usr/local/nagios/libexec/check_nrpe -H 10.11.27.44
Теперь наша попытка успешна и мы видим версию nagios
Снова открываем основной конфиг
Снимаем знак комментария со строки с cfg_dir (cfg_dir=/usr/local/nagios/etc/servers)
Создаем директорию и переходим в нее
mkdir /usr/local/nagios/etc/servers
cd /usr/local/nagios/etc/servers
Определяем хосты, мониторинг которых будет производиться. У хостов могут быть любые названия, nagios увидит все файлы с расширением cfg
Прописываем параметры хоста, значения директив понятно из названия. Этих директив может быть значительно больше в случае необходимости тонких настроек мониторинга, здесь рассматираем базовую рабочую конфигурацию
define host {
use linux-server
host_name cenos11
alias just nagios client
address 10.11.27.44
max_check_attempts 5
check_period 24×7
notification_interval 30
notification_period 24×7
}
Добавляем конфиг для сервиса, который мониторим. Сейчас ограничимся проверкой наличия пинга до хоста
{
use generic-service
host_name cenos11
service_description PING
check_command check_ping!100.0,20%!500.0,50%
}
Использована команда check_command, выдержка из мануала относительно нее говорит следующее:
check_ping -H -w ,% -c ,%
[-p packets] [-t timeout] [-4|-6]
Соответственно, при потере 20% пакетов мы будем получать предупреждение, при потере 50% — ALERT
Снова запускаем и убеждаемся в том, что ошибок нет
/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Перезапускаем службу
systemctl restart nagios
Идем в веб-интерфейс и видим, что там отображается сервис на удаленном хосте, который мы мониторим (в конфигурации, приведенной на скриншоте, настроен мониторинг еще ряда ресурсов). Настройка сервера мониторинга с базовым функционалом завершена.
Настройка ALERT-ов в nagios
Открываем основной конфигурационный файл и при необходимости раскомментируем строку cfg_file=/usr/local/nagios/etc/objects/contacts.cfg :
mcedit /usr/local/nagios/etc/nagios.cfg
В файле определяем контактный адрес электронной почты для отправки уведомлений:
mcedit /usr/local/nagios/etc/objects/contacts.cfg
define contact {
contact_name nagiosadmin
use generic-contact
alias Nagios Admin
email [email protected]
}
Перезапускаем службу
cyctemctl restart nagios
Также может использоваться дополнительное программное обеспечение с помощью которого могут отправляться, например, SMS-сообщения с ALERT -ами касающимися принципиально важных сервисов. Получен рабочий сервер Nagios, установка и настройка на этом завершены.
Для серверов можно устанавливать Nagios сервер и клиент на одной машине, однако намного проще использовать другой пакет — например, .
Для начала на server01 необходимо установить пакет nagios. Для этого введите в терминале:
Sudo apt-get install nagios3 nagios-nrpe-plugin
Вам будет предложено ввести пароль для пользователя nagiosadmin . Учетные записи пользователя находятся в /etc/nagios3/htpasswd.users. Для смены пароля пользователя nagiosadmin или добавления других пользователей для выполнения CGI скриптов Nagios используйте утилиту htpasswd , которая является частью пакета apache2-utils .
Например, для смены пароля пользователя nagiosadmin введите в терминале:
Sudo htpasswd /etc/nagios3/htpasswd.users nagiosadmin
Для добавления пользователя:
Sudo htpasswd /etc/nagios3/htpasswd.users steve
Sudo apt-get install nagios-nrpe-server
NRPE позволяет выполнять локальные проверки на удаленном компьютере. Но существуют и другие способы достижения этой цели, используя другие плагины Nagios, также как и другие способы проверок.
Обзор файлов настройки
Существует несколько директорий, содержащих конфигурационные файлы Nagios, а также файлы проверок.
1. /etc/nagios3: содержит конфигурационные файлы для работы демона nagios, файлы CGI , описания компьютеров и т.д.
2. /etc/nagios-plugins: файлы конфигурации для служебных проверок.
3. /etc/nagios: содержит конфигурационные файлы на удаленном компьютере nagios-nrpe-server .
4. /usr/lib/nagios/plugins/: тут находятся бинарные проверки. Для просмотра опций проверки используйте ключ "-h".
Например: /usr/lib/nagios/plugins/check_dhcp -h
Существует множество проверок Nagios, которые могут быть настроены для выполнения на любом компьютере. В этом примере Nagios будет настроен на проверку дискового пространства, службы DNS , а также группы пользователей MySQL. Проверка DNS будет осуществятся на server02 , а группа компьютеров MySQL будет включать в себя как server01 так и server02 .
Смотрите раздел HTTPD - Apache2 Web Server для более детальных настроек Apache, Служба Доменных Имен (DNS) для настройки DNS , а также MySQL для настройки MySQL .
В дополнение к этому будут приведены несколько терминов, которые помогут вам облегчить настройку Nagios:
Компьютер (хост): сервер, рабочая станция, сетевое устройство и т.д., которое отслеживается.
Группа компьютеров: группа подобных компьютеров. Например вы можете сгруппировать все веб-сервера, файловые сервера и т.д.
Служба: служба, которая отслеживается на компьютере. Например HTTP , DNS , NFS и т.д.
Группа служб: позволяет объединить несколько служб вместе. Например это будет полезным для объединения нескольких веб-серверов.
Контакт: человек, который будет уведомлен при каком-либо событии. Nagios может быть настроен на отправку email, SMS-сообщений и т.д.
По умолчанию Nagios настроен на проверку HTTP , дискового пространства, SSH , текущих пользователей, процессов и слежение за уровнем загрузки на локальном компьютере. Nagios также выполняет проверку шлюза посредством команды ping .
Совокупность установленных систем Nagios могут быть настроены комплексно. Начать лучше с нескольких компьютеров, одного или двух, а затем настроить оптимальным образом вместо использования дополнений.
Настройка
1.1. Для начала необходимо создать конфигурационный файл для server02 . Если не указанно иное, выполните все эти команды на server01 . Введите в терминале:
Sudo cp /etc/nagios3/conf.d/localhost_nagios2.cfg \ /etc/nagios3/conf.d/server02.cfg
В вышеуказанном, а также следующем примере замените «server01», «server02» 172.18.100.100 и 172.18.100.101 на имя и ip-адрес ваших серверов.
Define host{ use generic-host ; Name of host template to use host_name server02 alias Server 02 address 172.18.100.101 } # check DNS service. define service { use generic-service host_name server02 service_description DNS check_command check_dns!172.18.100.101 }
1.3. Перезагрузите демон nagios для активации новых настроек:
2.1 Теперь добавим служебное описание для проверки MySQL путем добавления следующих строк в /etc/nagios3/conf.d/services_nagios2.cfg:
# check MySQL servers. define service { hostgroup_name mysql-servers service_description MySQL check_command check_mysql_cmdlinecred!nagios!secret!$HOSTADDRESS use generic-service notification_interval 0 ; set > 0 if you want to be renotified }
2.2. Сейчас должны быть определены сервера группы mysql. Отредактируйте /etc/nagios3/conf.d/hostgroups_nagios2.cfg добавив следующее:
# MySQL hostgroup. define hostgroup { hostgroup_name mysql-servers alias MySQL servers members localhost, server02 }
Mysql -u root -p -e "create user nagios identified by "secret";"
Пользователь nagios должен присутствовать на всех компьютерах рабочей группы серверов mysql.
2.4. Перезагрузите nagios для проверки сервера MySQL.
Sudo /etc/init.d/nagios3 restart
3.1. Наконец необходимо настроить NRPE для проверки дискового пространства на server02 .
На server01 добавим служебную проверку в /etc/nagios3/conf.d/server02.cfg:
# NRPE disk check. define service { use generic-service host_name server02 service_description nrpe-disk check_command check_nrpe_1arg!check_all_disks!172.18.100.101 }
3.2. Теперь на server02 отредактируем /etc/nagios/nrpe.cfg:
Allowed_hosts=172.18.100.100
А в строку объявления команды добавим:
Command=/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -e
3.3. В конце перезагрузим nagios-nrpe-server:
Sudo /etc/init.d/nagios-nrpe-server restart
3.4. На server01 также необходимо перезагрузить nagios:
Sudo /etc/init.d/nagios3 restart
Теперь вы должны видеть ваши сервера и служебные проверки в файлах Nagios CGI . Для доступа к ним наберите в строке браузера http://server01/nagios3 . Вам будет предложено ввести имя пользователя и пароль для nagiosadmin.
Ссылки
В этом разделе были описаны лишь незначительные возможности Nagios. nagios-plugins-extra и nagios-snmp-plugins содержит намного больше файлов проверки служб.
1. Для более детальной информации обратитесь к документации на официальном сайте Nagios .
2. Узконаправленная документация по Nagios .
3. Существует несколько книг посвященных Nagios и мониторингу сети.
4. Страница Nagios Ubuntu Wiki также содержит достаточно документации.
В настоящее время все больше малых и средних компаний создают распределенную ИТ-инфраструктуру, неотъемлемой частью которой является эффективный мониторинг всех ее составляющих для обеспечения непрерывного и качественного функционирования. К подобным решениям обычно предъявляются следующие нефункциональные требования: быстрая реакция на события и способность работать на ограниченных вычислительных ресурсах. В данной статье описывается возможность построения подобной системы на основе свободно распространяемого ПО для мониторинга - Nagios.
Краткое описание Nagios
Главный компонент Nagios, базовый сервер, может быть развернут практически на любом Linux/Unix сервере. Он входит практически во все распространенные дистрибутивы Linux и Unix. При необходимости с сайта проекта можно загрузить исходный код и собрать на его основе собственную версию Nagios. Также вместе с основным пакетом Nagios устанавливается и документация для него.
Nagios обладает модульной архитектурой с возможностью расширения. Для увеличения возможностей Nagios можно использовать компоненты следующих типов: плагины (Nagios plugins) и расширения (Nagios addons).
Плагины используются основным процессом Nagios для получения следующей информации: время отклика удаленного узла, свободное место на дисковом разделе и т.д. Если плагин с требуемой функциональностью найти не удалось, то предлагается удобный интерфейс для создания собственных плагинов.
Термин «расширение» (addon) был введен, чтобы избежать путаницы с плагинами, так как расширения используются для добавления в Nagios принципиально новой функциональности или интеграции с другими внешними продуктами.
Возможность быстрого написания плагинов превратила Nagios в универсальное средство для сетевого мониторинга. Существуют плагины для опроса узлов по SNMP, проверки доступности удаленного узла по множеству сетевых протоколов. В проекте Nagios Exchange можно выполнить поиск среди уже написанных плагинов или расширений, или добавить туда плагин собственной разработки.
Пользовательский интерфейс Nagios реализован в виде Web-приложения. Необходимые CGI-сценарии и конфигурация Web-сервера входит в базовый комплект Nagios. Также имеется подсистема оповещения, позволяющая информировать по email о возникновении нештатных ситуаций и их устранении.
На рисунке 1 представлена структура основного сервера Nagios.

На рисунке 2 показан механизм запуска плагинов Nagios на удаленном узле.

Ключевыми компонентами на рисунке 2 являются плагин check_nrpe на стороне узла мониторинга и расширение NRPE на удаленном узле. Между плагином check_nrpe и NRPE -демоном устанавливается зашифрованное SSL соединение, по которому nagiosd отправляет команды для запуска плагинов и получает результаты их выполнения. NRPE «проецирует» плагины на удаленном узле в основной сервер Nagios (nagiosd ), благодаря чему можно запускать любые плагины на любом удаленном узле.
Для удаленного мониторинга Windows узлов можно использовать расширение NSClient++ . В данном случае со стороны nagiosd должен использоваться плагин check_nt .
Пример использования Nagios
Для примера будет взято малое торговое предприятие, имеющее 3 точки присутствия: склад, магазин и офис. У каждой точки присутствия имеется свое подключение к местному ISP. В качестве шлюза на каждой из площадок установлен Linux/Unix сервер. Между всеми площадками организован VPN. В офисе Интранет-сеть - 10.1.0.0/24. На складе - 10.2.0.0/24. В магазине - 10.3.0.0/24. Руководством предприятия была поставлена задача осуществить мониторинг данной ИТ-инфраструктуры.

Для этого потребуется установить на каждый из серверов службу NRPE и на двух из них базовый комплект Nagios. Это делается для того, чтобы, если произойдет отключение одного из серверов Nagios, то другой немедленно бы отправил сообщение об этом.
Для установки nagiosd и NRPE можно использовать штатные средства системы. Эта процедура зависит от выбранной платформы и обычно трудностей не представляет. Также вместе с nagiosd или NRPE устанавливается базовый комплект плагинов. Еще потребуется установить и настроить Web-интерфейс для отображения состояния узла c установленным Nagios сервером. В некоторых дистрибутивах он выделен в отдельный пакет. Наконец, необходимо создать файл htpasswd с пользователем nagiosadmin, прописанным в файле cgi.conf. При желании вместо этого имени можно внести изменения в конфигурацию и использовать другого пользователя.
После этого можно запустить Nagios-сервер и Web-сервер и войти на локальный ресурс Nagios, введя имя пользователя и пароль. Пока он осуществляет мониторинг только одного узла localhost и показывает несколько его параметров (load average (средняя загрузка), current users (активные пользователи) , disk space (дисковое пространство)). В одном из разделов этого ресурса находится документация, так что для доступа к ней не потребуется расходовать Интернет-трафик. Описание узла находится в файле localhost.cfg.

Прежде чем добавлять в конфигурацию другие узлы, необходимо указать e-mail адреса людей, отвечающих за их администрирование. Это делается в файле contacts.cfg. Крайне рекомендуется выбирать e-mail адреса независимых провайдеров электронной почты. Например, можно установить на мобильный телефон почтовый клиент Yandex и указать в описании адрес на yandex.ru. Если Интернет в офисе, где установлен корпоративный почтовый сервер, будет отключен, то даже в нерабочее время Nagios сервер со склада уведомит администратора об этом через мобильный телефон.
В листинге 1 показано, как добавить контактную информацию в файл contacts.cfg.
Листинг 1. Добавление контактной информации.
define contact{ contact_name zorin; // короткое имя пользователя // значения по умолчанию будут унаследованы от шаблона generic-contact use generic-contact; alias Alexander N. Zorin; // полное имя пользователя email [email protected]; }После этого необходимо зарегистрировать узлы, мониторинг которых будет осуществляться, в Nagios. В листинге 2 показано, как по аналогии с файлом localhost.cfg, создать описание складского узла в файле warehouse-gw.cfg.
Листинг 2. Добавление узлов в Nagios.
define host{ // название шаблона, используемого для описания узла. // определение этого узла унаследует все параметры, // объявленные в шаблоне узла linux-server. use linux-server host_name warehouse-gw alias warehouse display_name Warehouse contacts zorin, worehouse-admin address 140.14.22.4 } define service{ // название шаблона, используемого для описания службы. use local-service ; host_name warehouse-gw service_description SSH check_command check_ssh notifications_enabled 1 } define host{ use linux-server; host_name warehouse-intra alias warehouse-intra display_name Warehouse local net contacts zorin, warehouse-admin address 10.2.0.1 } define service{ // название шаблона, используемого для описания службы. use local-service; host_name warehouse-intra service_description SMTP check_command check_smtp notifications_enabled 1 }Узел warehouse-gw намеренно зарегистрирован дважды, чтобы отслеживать состояние как внешних, так и внутренних служб локальной сети. В данном примере SMTP-сервер обслуживает только локальную сеть. В сводках на Web-интерфейсе Nagios будут показываться два узла warehouse-gw и warehouse-intra . Если пропадет узел warehouse-intra и будет доступен только warehouse-gw – это значит, что произошло отключение VPN-канала.
Часть плагинов будет запускаться через расширение NRPE (load average - check_load, disk space - check_disk, current users - check_users) для получения информации, которую невозможно или сложно получить, находясь вне узла. Для этого потребуется установить плагин check_nrpe2 на Nagios серверах и расширение NRPE на всех серверах. Это можно сделать с помощью стандартных средств системы.
В конфигурационном файле nrpe.cfg обязательно нужно прописать адрес, к которому будет прикреплен NRPE -демон и доверенные узлы, от которых он будет принимать запросы. Для магазина (узел shop-gw) будут использоваться следующие параметры:
server_address=10.3.0.1 allowed_hosts=10.1.0.1,10.2.0.1Трафик NRPE намеренно направляется через VPN. Доверенными узлами для NRPE-демона в магазине являются офис и склад. На Nagios-серверах мониторинг данных служб будет настроен, как показано в листинге 3:
Листинг 3. Настройка мониторинга для удаленной службы
define service{ // название шаблона, используемого для описания службы. use local-service; host_name warehouse-intra service_description Load average index check_command check_nrpe2!-c check_load notifications_enabled 1 }В данном случае NRPE -демону узла warehouse-intra отправляется команда check_load . В ответ будет прислано текущее значение load average для этого узла. Следует обратить внимание, что параметры для плагина (а их может быть несколько) должны быть разделены восклицательными знаками. В представленном примере параметром является -c check_load .
Так, шаг за шагом, за счет добавления новых узлов и отслеживаемых на них параметров строится высокофункциональная система мониторинга.
Работа с плагинами
Плагины - это простые программы или сценарии, получающие входные параметры при запуске через параметры командной строки и возвращающие запрашиваемые значения в stdout в строго определенном формате. Команды для запуска плагинов могут быть прописаны в файле commands.cfg, при этом плагины, установленные вместе с nagiosd , уже находятся в этом файле. Также есть возможность прописать каждый плагин в отдельном файле.
В листинге 4 показано, как описывается плагин check_smtp , проверяющий доступность SMTP-сервера на удаленном узле и время его отклика.
Листинг 4. Настройка плагина check_smtp
define command{ command_name check_smtp command_line /usr/lib/nagios/plugins/check_smtp -H $HOSTADDRESS$ }Здесь явно указаны путь к плагину check_smtp и необходимость добавлять к запросу через опцию -H IP адрес проверяемого узла, который подставляется автоматически на основании директивы define service , приведенной выше. Если запустить данный плагин из командной строки, то будет выведена следующая информация:
/usr/lib/nagios/plugins/check_smtp -H 192.168.4.1 SMTP OK - 0.038 sec. response time|time=0.037518s;;;0.000000Параметры запуска могут быть различными, главное правильно добавить их в описание команды. Формат вывода подробно описан в документации, установленной вместе с Web-интерфейсом.
При установке NRPE -демона в файле nrpe.conf прописывается лишь незначительная часть плагинов, среди них - приведенная выше команда chесk_load :
command=/usr/lib/nagios/plugins/check_load -w 15,10,5 -c 30,25,20В приведенной строке указан путь к плагину check_load и параметры его запуска. Если плагин запустить без параметров, то он выведет список допустимых параметров. Например, необходимо создать команду check_usr для NRPE , которая бы возвращала на сервер мониторинга информацию о разделе /dev/md2, смонтированном на пути /usr. Данную функциональность можно реализовать с помощью стандартного плагина check_disk . Если запустить его без параметров, то будет выведено описание стартовых параметров.
Usage: check_disk -w limit -c limit [-W limit] [-K limit] {-p path | -x device} [-C] [-E] [-e] [-g group ] [-k] [-l] [-M] [-m] [-R path ] [-r path ] [-t timeout] [-u unit] [-v] [-X type]На основании представленной информации можно подготовить команду check_usr и поместить ее в файл nrpe.conf:
command=/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -p /dev/md2Пробный запуск этой команды выдаст результат:
/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -p /dev/md2 DISK OK - free space: /usr 20295 MB (86% inode=92%);| /usr=3061MB;19684;22145;0;24606Как видно, в Nagios можно легко создавать плагины для выполнения самых разных задач и подключать их к NRPE-демону.
Расширения Nagios
Обсуждая возможности Nagios, обязательно нужно рассмотреть наиболее интересные расширения, значительно повышающие возможности Nagios.
Расширение pnp4nagios
По умолчанию Nagios хранит историю изменения состояния отслеживаемых параметров только по уровню их критичности (норма, предупреждение, критическое состояние). Пользователь может посмотреть, в какие периоды параметр находился в различных состояниях и каково было суммарное время пребывания в этих состояниях за отчетный период.

Как показано на рисунке 5, красным цветом выделен период критичного состояния, а зеленым - периоды нормального функционирования. Такое решение подходит для параметров логического типа (да/нет), например, целостности RAID массива. Для численных параметров было бы полезнее отслеживать динамику изменений.
Расширение pnp4nagios , регулярно получая от nagiosd значения параметров, сохраняет историю их изменений и формирует отчет в графической форме. Графики можно произвольно комбинировать и при необходимости конвертировать полученную Web-страницу в PDF-файл. На рисунке 6 продемонстрирован отчет об изменении параметра load average для конкретного узла.
Рисунок 6. Web-страница расширения pnp4nagios
ЗаключениеОсобенно стоит отметить низкую ресурсоёмкость этого решения. В одной из компаний Nagios используется для мониторинга 14 узлов и 140 служб на них, при этом NRPE-демон занимает 512КБ оперативной памяти, а сервер nagiosd всего 140КБ оперативной памяти. Потребление ресурсов процессора обоими компонентами и их дочерними процессами на CPU Pentium-IV не превышает 1%. Среди отслеживаемых параметров: температура винчестеров и материнских плат, состояние дисковых разделов, размеры почтовых очередей, скорости вращения вентиляторов, целостность RAID массивов и многое другое.
Как было показано в этой статье, пакет Nagios обладает крайне низкими требованиями к ресурсам, богатыми возможностями для настройки и открыт для добавления новых плагинов и расширений. Для малой или средней компании, у которой уже есть хотя бы один Linux/Unix сервер, Nagios является идеальным решением для организации мониторинга существующей IT-структуры.